In last week’s post, I wrote about the basics of fetching JSON data over HTTP in Haskell. This week, we’ll show how to take this data, manipulate it using pure, testable Haskell functions, and then insert into into our PostgreSQL database using the IHP web framework.
Building the data we need
As a reminder, the data we scraped last week was information about live concert recordings
hosted on the Live Music Archive. These were modeled as an ArchiveItem.
data ArchiveItem = ArchiveItem
{ identifier :: Text,
date :: Text,
collection :: Maybe Text,
transferer :: Maybe Text,
downloads :: Maybe Int,
source :: Maybe Text,
avgRating :: Maybe Text,
numReviews :: Maybe Int,
lineage :: Maybe Text,
coverage :: Maybe Text,
venue :: Maybe Text
}
deriving (Show, Generic, Eq)
For Attics, however, users do not want to browse through individual items. Rather, when they’re looking for something to listen to, normally they have a specific performance in mind, and will then choose the recording that suits what they want for that performance, such as an audience recording where you can hear the sounds of the crowd, or a soundboard recording where you can hear every note clearly.
With this in mind, we have two distinct objects in our app: performances, which represent a concert performed on given date,
and recordings, which are recordings of a performance. Let’s use the Schema Editor in the IHP IDE to create tables
in PostgresSQL for these types, and then we’ll be able to use the autogenerated Haskell types to finally transform
ArchiveItems.
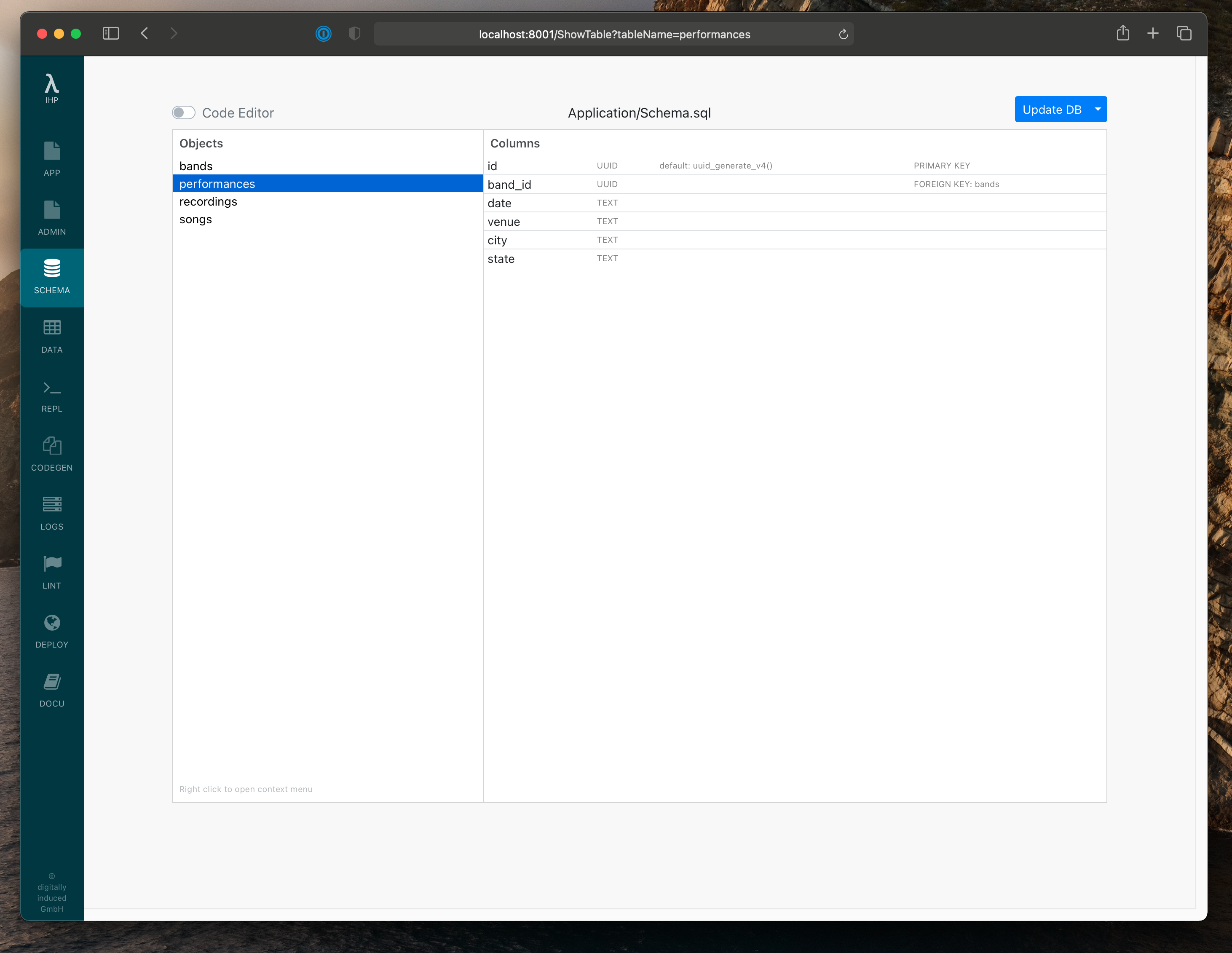
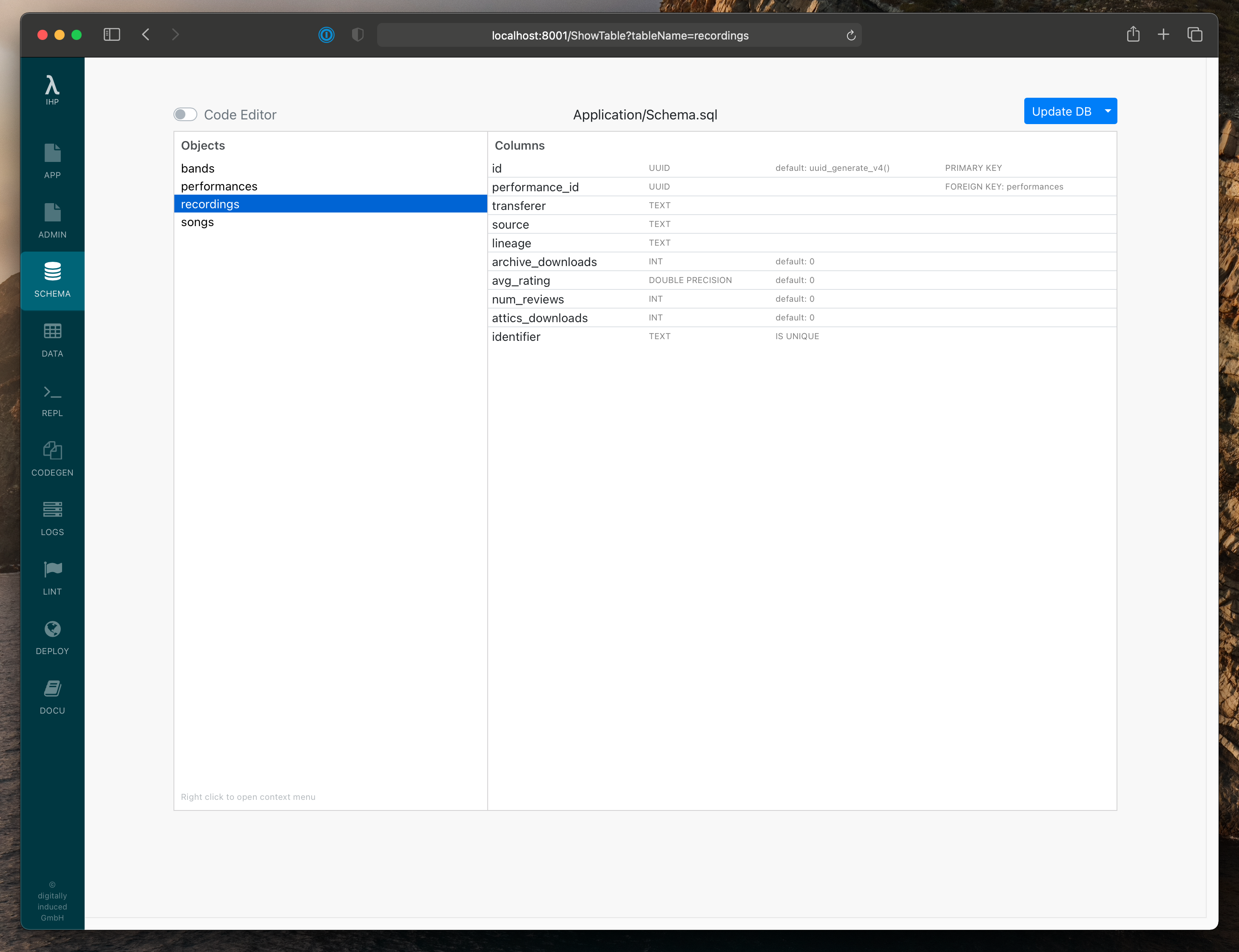
With the types added in the database, we can now use the Performance and Recording types in Haskell. Unfortunately, in our case ArchiveItem does not map exactly to either Performance or Recording: it contains recording data, but also data about the performance more generally, such as the venue, date, and coverage (Archive term for location). We also have some extra fields in the database models that aren’t scraped, such as attics_downloads, the amount of times a recording has been downloaded through the app, and performance_id, a reference to its parent performance.
Data pipeline
Since what we’re scraping doesn’t map exactly to our database models, we’ll need a data pipeline to transform the incoming data to what we can store. Here’s the way I came up with:
- Scrape ArchiveItems
- Create a list of RecordingDatas from the ArchiveItems
- Create Performances from RecordingDatas and insert into DB
- Using IDs of newly inserted Performances, create Recordings and insert into DB
To make things easier, let’s define an intermediate data type named RecordingData, which will contain fields of ArchiveItem formatted into appropriate form for Attics.
data RecordingData = RecordingData
{ identifier :: Text,
collection :: Text,
date :: Text,
venue :: Text,
city :: Text,
state :: Text,
transferer :: Text,
source :: Text,
lineage :: Text,
downloads :: Int,
avgRating :: Double,
numReviews :: Int,
atticsDownloads :: Int
}
deriving (Show)
To construct a RecordingData record, let’s define a function archiveToAttics that
creates a RecordingData from an ArchiveItem.
archiveToAttics :: Text -> ArchiveItem -> RecordingData
archiveToAttics defaultCollection ArchiveItem {..} =
RecordingData
{ collection = fromMaybe defaultCollection collection,
identifier = identifier,
date = Text.takeWhile (/= 'T') date,
transferer = fromMaybe "Unknown" transferer,
downloads = fromMaybe 0 downloads,
source = fromMaybe "Unknown" source,
avgRating = fromMaybe 0 (avgRating >>= readMaybe . cs),
numReviews = fromMaybe 0 numReviews,
lineage = fromMaybe "Unknown" lineage,
venue = fromMaybe "Unknown" venue,
city = city,
state = state,
atticsDownloads = 0
}
where
-- parse the coverage field which is usually of the form City, State
(city, state) = fromMaybe ("Unknown", "Unknown") $ do
str <- coverage
let s = Text.splitOn "," str
if List.length s == 2
then pure (fromMaybe "Unknown" $ head s, Text.strip (s !! 1))
else Nothing
A couple notes:
- Here we make extensive use of
fromMaybe :: a -> Maybe a -> a
which is a great way to provide default values for Maybe fields.
- The most confusing part here is likely
avgRating >>= readMaybe . cs. You’ve likely mainly seen the bind operator>>=used in IO contexts – but actually it works for all monads , and sinceMaybeis a Monad, we can use bind here to perform a function ifavgRatinghas a value. This code is equivalent to
case avgRating of
Nothing -> Nothing
Just avgRating -> readMaybe (cs avgRating)
Grouping Data: foldr and Hash Maps
Now it’s time to generate Performances from our collection of recording data. The first step is to group the recording data by date. Then, using the recordings for a given date, we can generate the data needed for a Performance. Get ready for a great example of functional programming :)
Let’s model this action with a function:
buildDateMap :: [RecordingData] -> HashMap Text [RecordingData]
How can we implement such a function? A helpful way before trying to write any code is to imagine an algorithm you could do manually, usually in an imperitive style.
- Start with an empty HashMap
- Loop through each item of the list
- Insert it into the HashMap using its date as the key
- Return the HashMap
The longer you work with Haskell and functional programming, the quicker you’ll be able to realize this is perfect
for a foldr, or in other language, reduce function. foldr takes an initial value, peforms some operation on it using each item of the list, and returns the final result.
Let’s get the function working first, then we’ll refactor it.
buildDateMap :: [RecordingData] -> HashMap Text [RecordingData]
buildDateMap =
foldr
(\recording map -> case HashMap.lookup (get #date recording) map of
Just list -> HashMap.insert (get #date recording) (list ++ [recording]) map
Nothing -> HashMap.insert (get #date recording) [recording] map)
HashMap.empty
For each recording, if the recording’s date is in the hash map already, add it to the list for the date, otherwise insert a new list for the date. There’s lots of ways this could be refactored, but searching through the documentation for HashMap, I found the insertWith function.
insertWith :: (Eq k, Hashable k) => (v -> v -> v) -> k -> v -> HashMap k v -> HashMap k v
Associate the value with the key in this map. If this map previously contained a mapping for the key, the old value is replaced by the result of applying the given function to the new and old value.
This function handles the case we manually checked for: that is, if the key already has a value or not. With insertWith, we can pass in a function that will generate a new value given the value already in hash map.
In the signature this is the first argument (v -> v -> v), taking two values and producing another. In our case, the values are of type [RecordingData]. How can you take two values of this type and produce a third? Immediately list contatenation should come to mind:
\listA listB -> listA ++ listB
Realize that although we normally use (++) as an infix operator, it’s just a function!
\listA listB -> (++) listA listB
This works exactly the same. Using point-free notation, the above is the same as just passing (++) itself!
So finally, we can write buildDateMap using insertWith and (++):
buildDateMap :: [RecordingData] -> HashMap Text [RecordingData]
buildDateMap =
foldr
(\recording -> HashMap.insertWith (++) (get #date recording) [recording])
HashMap.empty
How cool is that! Credit to Matt Parsons’s Production Haskell book for inspiring this method :)
Building a Performance from many Recordings
Recall that nearly all fields of ArchiveItem were optional. Because of this, we can’t just take the first
recording of each group and use it to get the location and venue info about the performance – it could be empty!
Instead, let’s search through all of the recordings for each date, and collect the non-empty information along the way, using the final result to build the performance.
buildPerformanceFromRecordings :: Band -> [RecordingData] -> Maybe Performance
Since Performance is related to a Band via its band_id field, we need to pass along a Band too.
Also, since the list of recordings could be empty, our result needs to be of type Maybe Performance.
The empty case is easy enough to implement:
buildPerformanceFromRecordings _ [] = Nothing
Let’s define a data type to keep track of our state.
data Builder = Builder {
band :: Band,
date :: Text,
venue :: Text,
city :: Text,
state :: Text,
recordings :: [RecordingData]
}
Now we can use the State monad to loop through the recordings, and
updating our Builder state with the venue, city, and state info
if it’s still “Unknown” until we are out of recordings, at which point
we use whatever we have to construct a new Performance using IHP’s newRecord and set.
buildPerformanceFromRecordings band (firstRecording : recordings) =
let firstState =
Builder
band
(get #date firstRecording)
(get #venue firstRecording)
(get #city firstRecording)
(get #state firstRecording)
recordings
in pure $ State.evalState (helper firstRecording) firstState
where
helper :: RecordingData -> State Builder Performance
helper firstSrc = do
Builder {..} <- State.get
case recordings of
[] ->
pure $
newRecord @Performance
|> set #date date
|> set #venue venue
|> set #city city
|> set #state state
|> set #bandId (get #id band)
(recording : rest) ->
let nextVenue = if venue == "Unknown" then get #venue recording else venue
nextCity = if city == "Unknown" then get #city recording else city
nextState = if state == "Unknown" then get #state recording else state
in do
State.put (Builder band date nextVenue nextCity nextState rest)
helper firstSrc
I’ve found this combination of State and recursion a very useful pattern!
Finally, we can transform RecordingData into an actual Recording.
makeRecording performanceId RecordingData {..} =
newRecord @Recording
|> set #identifier identifier
|> set #performanceId performanceId
|> set #transferer transferer
|> set #source source
|> set #lineage lineage
|> set #archiveDownloads downloads
|> set #avgRating avgRating
|> set #numReviews numReviews
Putting it all together: writing the Script
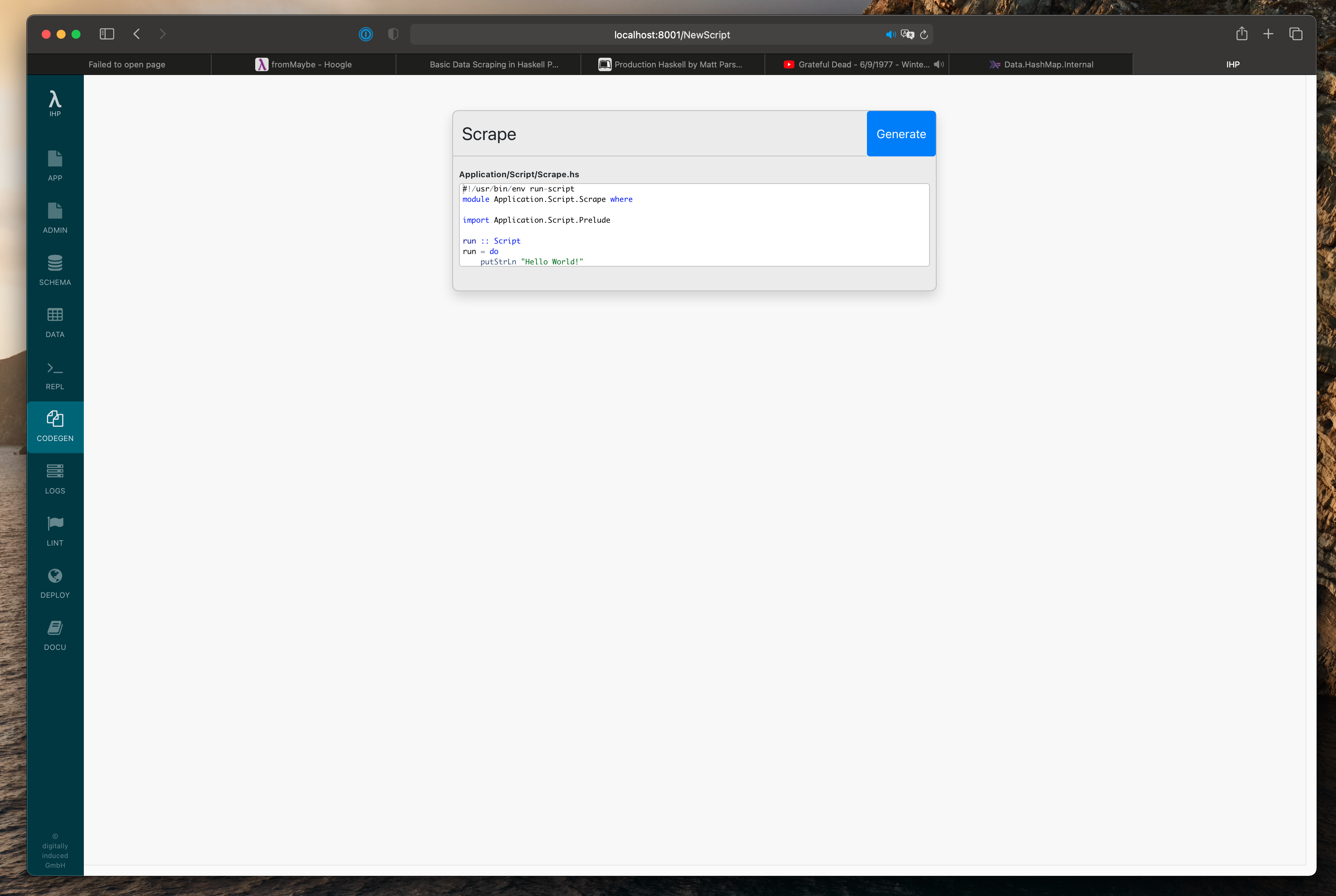
To run arbitrary scripts outside of the normal request lifecycle, IHP provides
the Script type and generator. A Script is just an IO () action with access to the database
through the implicit modelContext parameter – no need to worry about the details, just realize you can
use the database like you can anywhere else in IHP.
Use the IHP IDE’s Codegen to generate an empty Script:
The rest uses what we’ve written last week and today and glues it all together to get the job done!
run :: Script
run = do
bands <- query @Band |> fetch
mapM_ runScrape bands
runScrape :: Band -> Script
runScrape band = do
(performances, recordings) <- scrapeCollection band
dbPerformances <- performances |> createMany
dbRecordings <-
map (makeRecording' dbPerformances) recordings
|> catMaybes
|> createMany
scrapeCollection :: Band -> IO ([Performance], [RecordingData])
scrapeCollection band = do
items <- scrape (get #collection band) -- get the ArchiveItems
let recordings = map (archiveToAttics (get #collection band)) items
let performances = buildPerformances band sources
pure (performances, recordings)
buildPerformances :: Band -> [RecordingData] -> [Performance]
buildPerformances band srcs =
mapMaybe (buildPerformanceFromRecordings band) groupedSources
where
groupedSources = HashMap.elems $ buildDateMap srcs
buildDateMap :: [RecordingData] -> HashMap Text [RecordingData]
buildDateMap =
foldr
(\src -> HashMap.insertWith (++) (get #date src) [src])
HashMap.empty
makeRecording' performances recording = do
performance <- findPerformance (get #date recording) perfs
let record = makeRecording (get #id performance) recording
pure record
findPerformance date performances = filter (p -> date == get #date p) performances |> head
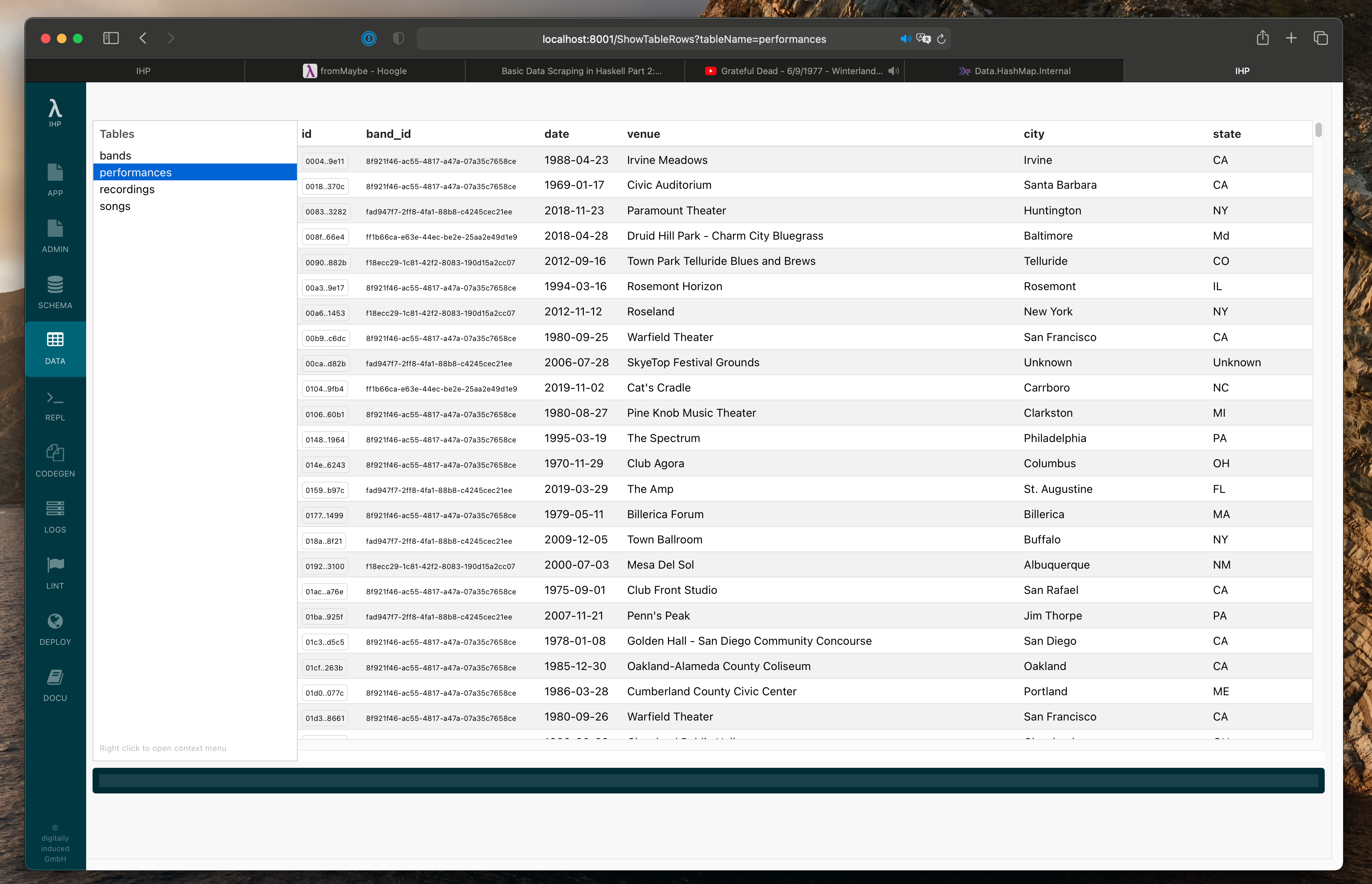
Result
After running the script with ./Application/Script/Scrape.hs, we can see in the IHP IDE that
the database is populated!
Conclusion
This turned out much longer than I had expected 😅 but I hope you found it useful! What we went though today is real code from my app Attics: to see it in context check it out on GitHub.
As always please feel free to comment below with any questions, ideas, or suggestions. Thanks for reading!